Transcribing Mixed Arabic-English Voice Messages: What We Learned from Real UAE Grocery Orders
We benchmarked Whisper, fine-tuned models, ElevenLabs, and Hamsa against 25 real WhatsApp voice notes — none hit production-grade accuracy.

Feb 19, 2026
TL;DR: We benchmarked OpenAI Whisper, a fine-tuned Hugging Face model, ElevenLabs, and Hamsa against 25 real-world WhatsApp voice notes from UAE grocery stores — messages where speakers freely switch between Gulf Arabic and English, often with an Indian accent. None of the off-the-shelf solutions hit production-grade accuracy. Here is everything we found, what improved results, and what didn't.
Why Mixed-Language Audio Is Still an Unsolved Problem
If you have ever tried running speech-to-text on a WhatsApp voice note from Dubai, you know the pain. A single 15-second message might contain a greeting in Arabic, a product name in English, a price in Arabic numerals, and a brand name pronounced with an Indian accent — all at once.
This pattern is called code-switching: speakers fluidly alternate between two or more languages within a single utterance. In the UAE, it is the norm, not the exception. Millions of daily voice messages on WhatsApp mix Gulf Arabic with English (and sometimes Hindi or Urdu), especially in commerce — grocery orders, restaurant supplies, delivery instructions.
Most speech-to-text APIs were built for monolingual audio. They assume one language per utterance, and they struggle — or fail silently — when that assumption breaks.
We set out to measure exactly how badly, and what can be done about it.
Our Test Setup
The Data
- 25 real WhatsApp voice messages from UAE-based grocery ordering
- Audio format: OGG/Opus (WhatsApp native), converted to WAV 16kHz mono
- Languages: Gulf Arabic with embedded English words and phrases
- Speakers: Multiple, including speakers with Indian accents
- Content: Product orders ("two boxes of Davidoff Gold"), scheduling ("come at 7 o'clock"), pricing ("170 dirhams"), and general conversation
Evaluation Methodology
Each sample was independently reviewed against its ground truth transcription by a single reviewer and classified into one of three categories:
- Accurate — The transcription captures all key information (products, quantities, prices, names) correctly. Minor spelling variations or filler words are acceptable. Roughly corresponds to WER < 20%.
- Partially correct — Some key information is correct but at least one significant element is wrong or missing (e.g., correct product but wrong quantity, or one of two items missing). Roughly corresponds to WER 20-50%.
- Major errors — The transcription is fundamentally wrong: wrong language detected, wrong products, hallucinated content, or completely unintelligible output. Roughly corresponds to WER > 50%.
Counts are per-sample (each voice message is one sample, not segmented). Where a sample falls on the boundary, the more severe category is chosen. Limitation: Classifications were performed by a single reviewer, which may introduce subjective bias, particularly for borderline Accurate/Partial cases. The "Major errors" category (wrong language, hallucinated content) is unambiguous; the boundary between "Accurate" and "Partially correct" carries more reviewer judgment.
What We Tested
| Approach | Description |
|---|---|
| OpenAI Whisper large-v3 | Baseline, the most widely used open-source STT model |
| Whisper + loudness normalization | Audio preprocessing with ffmpeg loudnorm before transcription |
| Whisper + multi-attempt | 3 transcription passes with different configs, pick best |
| Whisper + audio chunking | Split audio into 5-second segments with 1-second overlap |
| Fine-tuned HF model | Arabic-Whisper-CodeSwitching-Edition, fine-tuned on Arabic-English code-switching data |
| LLM post-processing | Send Whisper output through an LLM for correction and cleanup with product catalog context |
| ElevenLabs | Commercial speech-to-text API (5 samples only) |
| Hamsa | Open-source Arabic-focused ASR by NADSOFT |
The Results: Whisper Baseline
Out of 25 samples with standard Whisper large-v3:
| Category | Count | Percentage |
|---|---|---|
| Accurate transcription | 6 | 24% |
| Partially correct | 8 | 32% |
| Major errors | 11 | 44% |
Only 24% of voice messages were transcribed accurately enough to be usable. Nearly half had critical errors — wrong products, wrong numbers, or completely hallucinated content.
The picture gets worse — not better — when you throw common improvement strategies at the problem:
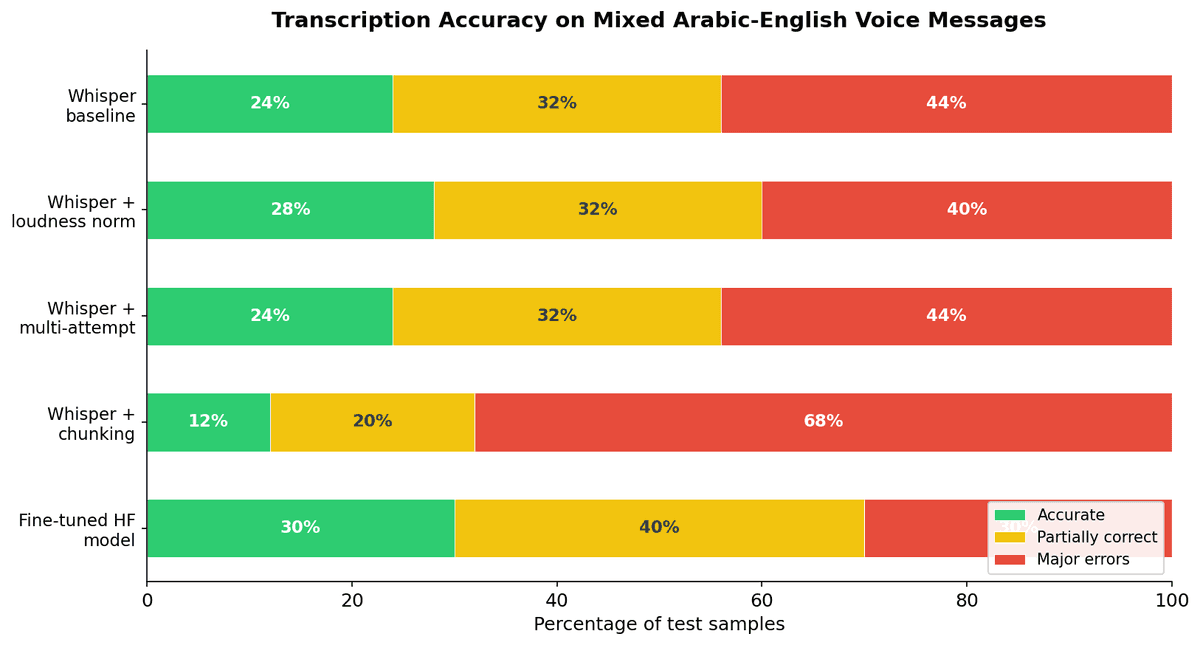
Chunking (splitting audio into 5-second segments) actually made things significantly worse, dropping accuracy to just 12%. The fine-tuned Hugging Face model showed the most promise at 30% accurate, but still far from production-ready. Multi-attempt transcription produced identical results to baseline — the same samples failed every time.
The Failure Modes
1. Wrong Language Detection
Whisper frequently misidentified the language entirely. Arabic audio was transcribed as Lithuanian, Indonesian, and even Punjabi. When the model picks the wrong language, every word in the output is wrong.
2. Number and Unit Confusion
Prices and quantities were consistently mangled — a critical failure for commerce. "170 dirhams" became "160 degrees." "Kilo of onions" became "kilo of mussels."
3. Hallucination and Repetition
Whisper sometimes hallucinated entire product names that were never spoken. The phrase "Lucien cake" appeared in 5 samples where it was never mentioned — a known bias from training data. Repetition was also common: greetings repeated 2–3 times, phrases looped.
4. Code-Switching Breakdown
When a speaker said "two boxes of Davidoff Gold" mid-sentence in Arabic, Whisper either translated everything to English (losing the Arabic context), kept everything in Arabic (mangling the English brand names), or mixed scripts incorrectly.
What We Tried to Fix It
Loudness Normalization — Low-Risk Win
Normalizing audio volume with ffmpeg before transcription provided marginal but consistent improvement. It is essentially free — no accuracy downside, slightly cleaner output on quiet recordings. We recommend enabling it by default.
Verdict: Keep it. Small gain, zero risk.
Multi-Attempt Transcription — No Measurable Improvement
Running 3 different transcription configurations per audio file and picking the best result sounds promising. In practice, all methods failed on the same samples and succeeded on the same samples. When Whisper misunderstands audio, trying again with slightly different settings produces the same wrong answer.
Verdict: Not worth the added latency and cost.
Audio Chunking (5-Second Segments) — Made Things Worse
Splitting audio into short chunks with overlap actually degraded quality. Short segments lost context, caused prompt text to leak into transcriptions, and produced artifacts like "Subtitles by the Amara.org community" appearing in output.
Verdict: Do not use chunking for short voice messages.
Fine-Tuned Arabic Code-Switching Model (Hugging Face)
We tested Arabic-Whisper-CodeSwitching-Edition, a model specifically fine-tuned for Arabic with English code-switching. Results were mixed:
Where it excelled: It handled code-switching better than base Whisper. A message like "I want one cheese croissant, fresh, okay?" was transcribed with English product names inline with Arabic — closer to how the speaker actually talked.
Where it struggled: Processing was ~8x slower (42 seconds vs ~5 seconds per sample). It still had trouble with unclear audio, Indian-accented Arabic, and number recognition. And it introduced its own errors.
Verdict: Better at code-switching preservation, but too slow and still unreliable on hard samples.
LLM Post-Processing — Effective Only When Whisper Gets It Mostly Right
We piped all transcription attempts through an LLM (with product catalog context of 11,844 items) to correct, translate, and clean up output. The LLM:
- Fixed "degrees" to "dirhams" (domain knowledge)
- Removed duplicate phrases and repetition
- Translated Arabic to clean English
- Standardized brand names using the product catalog
But it cannot fix what Whisper fundamentally got wrong. When the base transcription says a customer ordered mussels instead of onions, or 16 grams instead of 170 dirhams, the LLM either propagates the error or makes a confident-sounding guess.
| Base Transcription Quality | LLM Effectiveness |
|---|---|
| Good (24% of samples) | Excellent — clean output, proper translation |
| Partial (32% of samples) | Moderate — fixes minor issues, misses major ones |
| Bad (44% of samples) | Minimal — cannot recover from wrong content |
Average confidence scores hovered at 0.50, with only 20% of corrections scoring above 0.70 — the LLM itself was uncertain about its fixes.
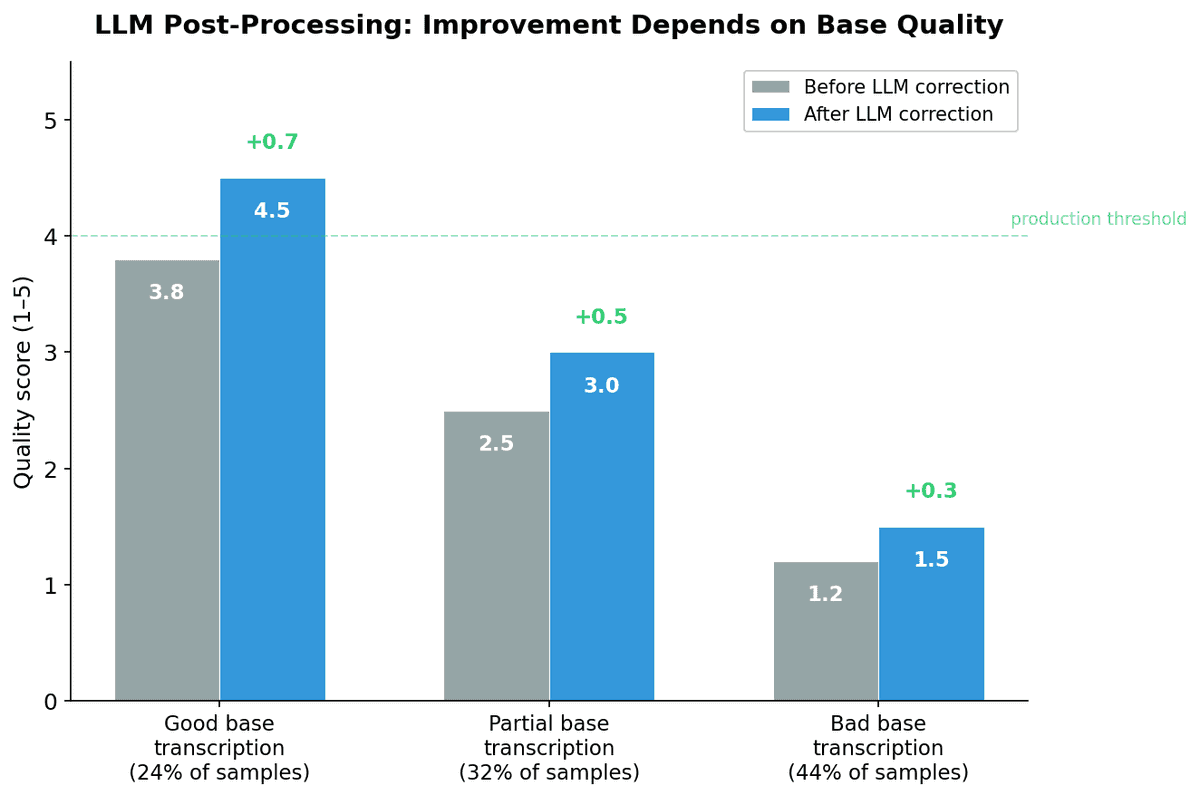
Verdict: Valuable as a cleanup layer, but not a substitute for accurate base transcription.
Commercial and Open-Source Alternatives
We also tested ElevenLabs (5 samples) and Hamsa (Arabic-focused open-source). Neither significantly outperformed Whisper on our mixed-language, Indian-accented samples. The core challenge — code-switching with non-native accents — is not solved by any single model we tested.
The Code-Switching Insight: Hint the Non-English Language
One discovery stood out. We ran a controlled test using Russian-English mixed audio (a language pair we could verify more easily) and found a critical configuration insight:
| Configuration | Code-Switching Preserved | Quality |
|---|---|---|
| Auto-detect | No (translates everything to English) | Good |
| English hint (-l en) | No (translates everything to English) | Good |
| Non-English hint (-l ru) | Yes | Best |
| Multilingual prompt | Partial | Poor |
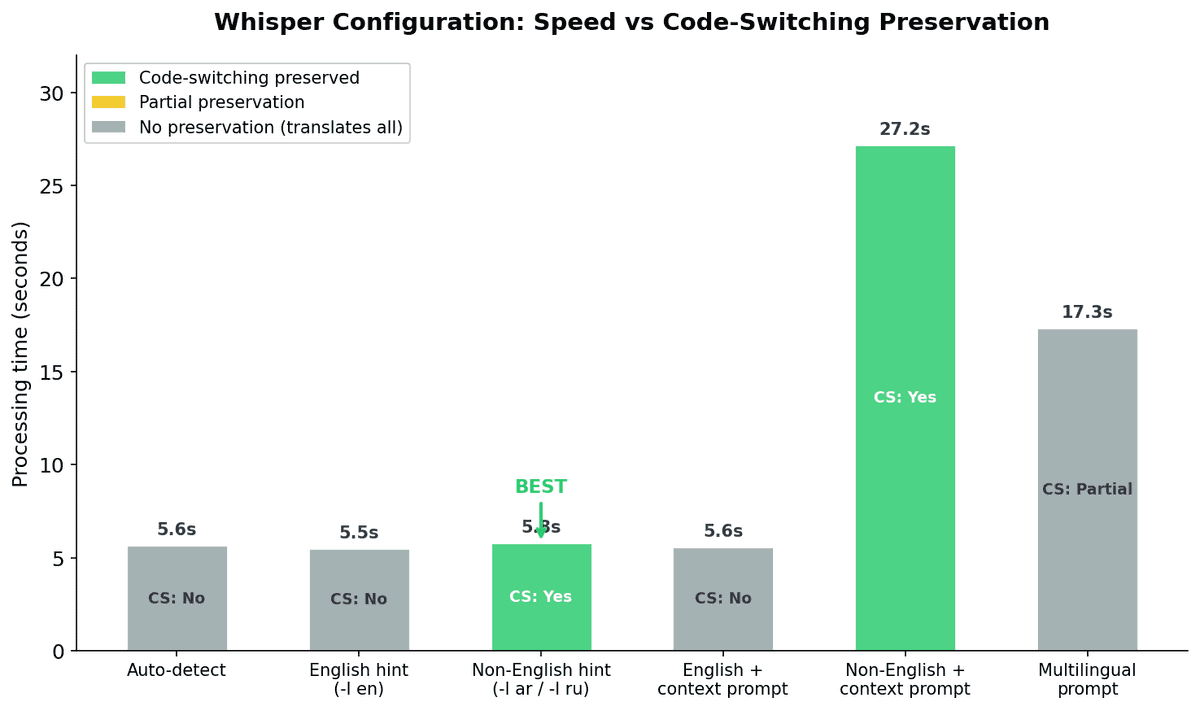
When you tell Whisper to expect the non-English language, it preserves code-switching — at the same speed as every other configuration (~5.8 seconds). With auto-detect or English hints, Whisper translates everything into one language, destroying the bilingual structure.
This applies to Arabic-English too: using -l ar preserves the natural code-switching better than auto-detect.
Key Takeaways for Building Multilingual STT
1. Off-the-shelf models do not solve code-switching at production quality
24% accuracy is not production-ready. If you are building voice-based workflows for multilingual markets like the UAE, plan for a significant engineering effort beyond "just use Whisper."
2. The bottleneck is base transcription, not post-processing
No amount of LLM correction, prompt engineering, or multi-attempt strategies can fix fundamentally wrong transcriptions. Investment should go into improving the base model — through fine-tuning on domain-specific data, accent-specific training, or hybrid architectures.
3. Audio preprocessing helps but does not move the needle significantly
Loudness normalization is worth enabling. Chunking is not. Multi-attempt transcription shows diminishing returns.
4. Language hints matter more than you think
For code-switching audio, always hint the non-English language. This single configuration change can be the difference between losing all bilingual structure and preserving it.
5. Indian-accented Arabic is particularly challenging
A significant portion of voice communication in UAE commerce comes from South Asian speakers using Gulf Arabic. This accent/dialect combination appears to be underrepresented in training data for most ASR models.
6. Domain context is valuable — when the base transcription is close
Product catalogs, brand name lists, and error pattern dictionaries genuinely help an LLM post-processing layer clean up output. But they only work when the raw transcription is in the right ballpark.
What is Next
We are actively working on:
- Fine-tuning on UAE-specific data — Gulf Arabic, Indian-accented Arabic, grocery domain vocabulary
- Hybrid pipeline architectures — combining the speed of Whisper with the accuracy of specialized models
- Confidence-based routing — using transcription confidence scores to decide when human review is needed vs. when automated processing is safe
- Expanded benchmarking — testing more commercial APIs and open-source models as the space evolves rapidly
Mixed-language voice transcription in markets like the UAE is a hard problem — but it is also a massive opportunity. The first team to solve it reliably unlocks voice-first commerce for millions of users.
At ReflektLab, we build AI-powered tools for commerce in multilingual markets. If you are working on similar challenges with Arabic speech recognition, multilingual transcription, or voice-based ordering systems, we would love to exchange notes.